This is all available on github: https://github.com/216software/ajax-put-rackspace.
We need to let users take files (possibly really big files) from their hard drive and push them straight to the Rackspace Cloud Files storage service.
We don't want the upload traffic anywhere near our servers.
Run the example
If you don't have a rackspace account, you're not going to be able to run this example, so go make one.
Also, my script depends on the Pyrax package, so install that, and then do this stuff:
$ git clone git@github.com:216software/ajax-put-rackspace.git
$ cd ajax-put-rackspace
$ python apr.py YOUR_RACKSPACE_USER_NAME YOUR_API_KEY
Now open up http://localhost:8765 and you should see something like the screenshot:

Now upload a file. Hopefully, you'll watch a pretty blue scrollbar track the upload's progress, and when it's done, you see something like what's in this screenshot:
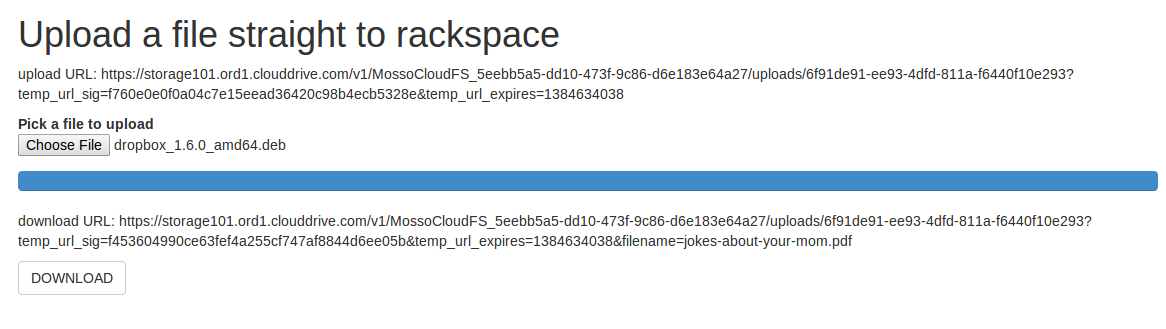
Click the DOWNLOAD button. You will get the file you uploaded, but named with a different name.
How we did it
- Make a container in rackspace cloudfiles.
- Set metadata on that container to allow CORS from the domain hosting our HTML file.
- Make a temp URL that we can upload to.
- Write HTML to build a simple input type=file widget.
- Write javascript so that when a user picks a file with the file input tag, we use a FileReader to read the contents of the file into a buffer.
- Use an ajax PUT to the temp URL created in step 3.
The python part
The Pyrax package made this easy. Here's how to work with pyrax:
$ pip install pyrax # this takes a while!
$ python
>>> import pyrax
>>> pyrax.set_setting('identity_type', 'rackspace')
>>> pyrax.set_credentials(YOUR_USER_NAME, YOUR_API_KEY, region="ORD")
You might need to set the region to something else besides ORD.
Now, make the container. Don't worry! Nothing stupid will happen if your “uploads” container already exists. You'll get a reference to the existing container:
>>> uploads_container = pyrax.cloudfiles.create_container('uploads')
Next set some metadata so that the browser will allow cross-domain AJAX:
>>> uploads_container.set_metadata({
'Access-Control-Allow-Origin': 'http://localhost:8765'})
Replace localhost:8765 with your domain and replace http with https if that's how you serve your site.
Next make a URL that you can give to the user's browser and say “send your data to this”:
>>> import uuid
>>> filename = str(uuid.uuid4())
>>> upload_url = pyrax.cloudfiles.get_temp_url(
uploads_container, filename, 60*60, method='PUT')
I'm using uuid.uuid4 to make a unique name, so that I never risk uploading on top of existing data.
The other two arguments to get_temp_url are the number of seconds that the URL lives for (60*60 means one hour) and the method='PUT' means this is a URL that the browser will push to, not pull from.
In other words, after an hour, requests won't succeed, and only PUT requests are allowed.
Like I said, the python part is really pretty easy!
Security considerations
The rackspace cloudfiles servers don't check if the request comes from from a user that authenticated with your web application. So, if anyone eavesdrops on the temporary URL we make, then anyone can push a file.
When you make a temporary URL, you need to make sure that the right person and only the right person gets it.
How to set the filename for downloads
Don't worry about how I'm using ugly-looking uuid filenames in the upload URL.
You can build links to the actual file with any name you want. You just need to add a query-string parameter “filename” to the link, like this:
download
The relevant rackspace documentation is here.
The javascript part
All the javascript lives in a big blob at the end of upload.html. It's a tangled mess of callbacks and closure variables.
I would love it if somebody forked this repository and sent me a pull request with a more elegant way to handle this stuff.
Here's what the code does:
- Sets an event listener on the on tag:
$("#upfile").on('change', function (e) {...
-
That event listener makes a FileReader instance named fr:
var fr = new FileReader();
- Then it sets a callback on the fr instance to handle when the fr instance finishes loading a file:
fr.onload = (function (file_object, input_file_node) {...
- Then it tells the fr instance to load in the file chosen by the user in the tag:
fr.readAsArrayBuffer(this.files[0]);
- When the fr instance finishes reading all the data from inside the file, the onload callback fires.
- The success callback for $.ajax request in this example code doesn't do anything interesting. It just un-hides the link to the download URL:
success: function (data) {
console.debug('Upload complete -- do what you want here');
$("div#download_url").collapse('show');
},
- It isn't necessary, but I want to show a progress bar in the browser as the file uploads. So I made my own xhr object for the $.ajax code to use, and that xhr object notices the “progress” event:
xhr: function() {var xhr = new window.XMLHttpRequest();
// Upload progress
xhr.upload.addEventListener("progress",function(evt) {{
if (evt.lengthComputable) {
var percentComplete = evt.loaded / evt.total;
console.debug('percentComplete: ' + percentComplete);
$("#progress-bar div.progress-bar").css('width',
String(100*percentComplete) + "%");}
},
false);return xhr;
},
Inside the onload callback, we use a good ol' jQuery $.ajax to send the data from the file to rackspace. It took us a while to figure out that the .result attribute holds data read in from the file:
$.ajax({
...
data: fr.result,
...
});
And that's about it! If the example doesn't work for you, please let me know. And I hope somebody can clean up the javascript! Triple-nested callbacks ain't my idea of a good time.
Alternate solutions
Handle the upload and then push to rackspace
The rookie solution involves writing some web application code to accept the file upload from the browser, save it to /tmp (or hell, just store it in memory), and then upload it to rackspace.
To be a little faster, perhaps just the first half happens during during the web request, and some unrelated background process uploads the file to rackspace later.
Risks with this approach
We're using the fantastic gunicorn WSGI server with regular synchronous workers.
Remember that with a synchronous worker, when a user makes a request, that request completely ties up the back-end worker process until it replies. That's why you need a bunch of sync workers working simultaneously. A request that comes in will get handled by one of the idle workers — as long as somebody is idle. Otherwise, requests queue up.
When too many users try to upload too many really big files at the same time, then all of the workers could be tied up, and the application would become unresponsive.
We could always just keep a ton of web application processes around, so that no matter how busy the application gets, we always have some idle workers, but that's a worst-case solution. That's like dealing with a weight problem by buying a bigger pair of pants.
What about using async workers?
Well, first of all, I want to get the files up to rackspace, and this way gets that done better.
But in other related scenarios, it would be nice to have the uploaded data in the application server.
Under the hood, these async libraries all monkey-patch stuff like the socket library, so that when you read or write from a socket, you automatically yield, so that other coroutines can use the CPU while you block for IO to complete.
Here's the problem that we ran into (which is likely totally fixable, or even never was broken).
We're using the werkzeug library to parse file uploads. It internally pulls data from the socket named “wsgi.input” passed in with the WSGI environ.
We couldn't figure out how to force the werkzeug request object to intermittently yield to the gevent scheduler while reading from the wsgi.input socket.
So while our async worker was reading the gigantic file being uploaded, even though the async worker was blocking on IO, it was not switching to go back and answer other requests.
I'd love to learn how to fix this, so please, help me out.